Here’s how to calculate the pedigree collapse effect in your own DNA matching discoveries. The bottom line may not be as scary as you thought for your genetic genealogy!
 In the first part of this two-part article, I defined how pedigree collapse (the intermarrying of ancestors with one another) may affect your genetic relatedness to your DNA matches. Here, learn when pedigree collapse might become significant to evaluating your genetic relationships to your matches, and how to calculate this effect in your own tree (it’s not as scary as it looks).
In the first part of this two-part article, I defined how pedigree collapse (the intermarrying of ancestors with one another) may affect your genetic relatedness to your DNA matches. Here, learn when pedigree collapse might become significant to evaluating your genetic relationships to your matches, and how to calculate this effect in your own tree (it’s not as scary as it looks).
Calculating shared DNA in pedigree collapse
This same systematic process described in the previous article can be applied to any relationship in the last several generations to determine an expected average amount of DNA sharing. So let’s bring this back to what you might see on your cousin match list.
If you see a match where you both descend through ancestors involved in pedigree collapse, what degree of elevated DNA sharing would you expect to see? Would it be enough to bump you up into a different relationship category? For example, if you were second cousins, would the elevated shared DNA be enough to make you look like you were 1st cousins perhaps? The Colapso family can help us answer that question.
Back to our example. Let’s determine the amount of shared DNA that would be expected between the cousins that are downstream from the event that initiated the collapse: when the two 1st cousins, Charlie and Cindy, had children together.
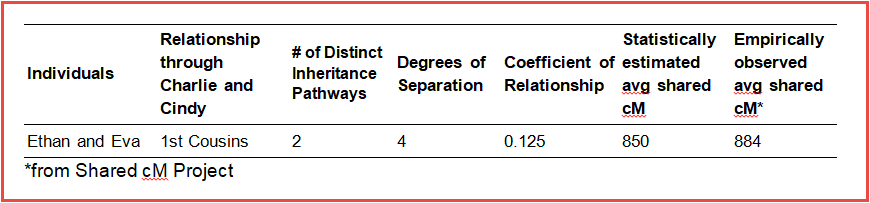
Ethan and Eva are 1st cousins through their common grandparents, Charlie and Cindy. As we explored earlier, it is expected that they would share on average 12.5% of DNA due to this 1st cousin relationship. However, because their grandparents are also 1st cousins themselves, Ethan and Eva are more genetically similar than cousins that descend through unrelated people. We can quantify this elevated level of DNA sharing by utilizing the coefficient of relationship.
First we’ll identify the distinct inheritance pathways that exist between Ethan and Eva, and the degrees of separation along each path. Isolating their closest relationship through their grandparents, Charlie and Cindy, Ethan and Eva share two distinct inheritance pathways: one through each grandparent. From Ethan there are two steps up to Charlie and two steps down to Eva (shown in red), making four degrees of relationship along that inheritance pathway. Similarly along the distinct path through Cindy (shown in blue), from Ethan there are two steps up to Cindy and two steps down to Eva, with four degrees of relationship between them.
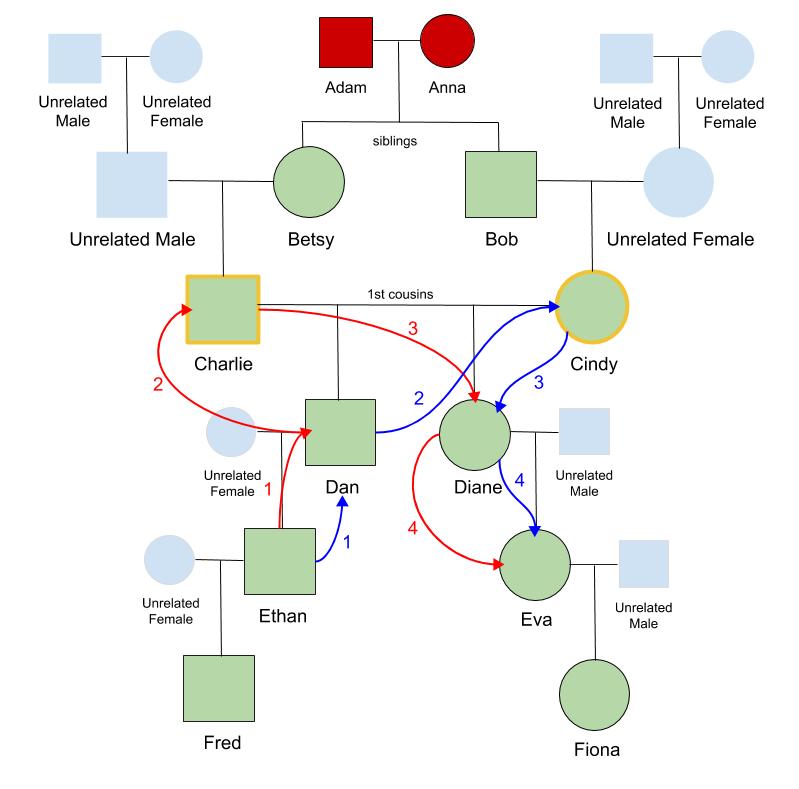
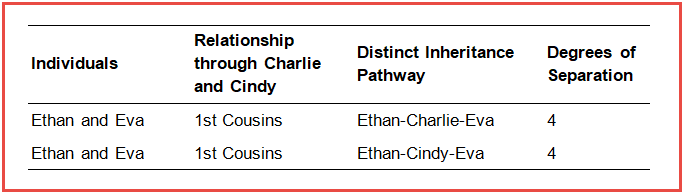
Using the same methodology explored previously we can calculate the coefficient of relationship for Ethan and Eva through their grandparents, Charlie and Cindy.

This means that focusing on their 1st cousin relationship, Ethan and Eva are expected on average to share 12.5% of their genome, or approximately 850 cM.
12.5% x 6800 cM = 850 cM
This could be the end of the story for predicting the expected amount of shared DNA for this relationship, except Ethan and Eva also share another set of recent common ancestors. Their great-grandparents, Adam and Anna, appear twice in their pedigree making only six unique great-grandparents rather than the typical eight. Ethan and Eva each have a double-dose of Adam and Anna floating around in their genetic make-up. This is what causes the elevated level of shared DNA in downstream descendants over what they would expect in the absence of pedigree collapse.
The figure below describes an important concept to draw out of this particular case study. Adam and Anna exist twice at the great-grandparent level. We want to calculate the amount of increased DNA sharing we would expect with this “double-dose” of the same ancestors. The inheritance pathways through one set of Adam and Anna contribute the typical amount of shared DNA to their downstream descendants, as would happen in the absence of duplicated ancestors. But the second set of Adam and Anna is the source of the increased DNA sharing in their descendants. We want to use the distinct inheritance pathways through this second set of Adam and Anna to augment the Coefficient of Relationship we’ve already determined for Ethan and Eva as 1st cousins through Charlie and Cindy. Due to this occurrence of pedigree collapse, they will share the typical amount of DNA that 1st cousins would, but we will add to it the coefficient of relationship determined through the pathways and degrees of separation through only the extra set of Adam and Anna.
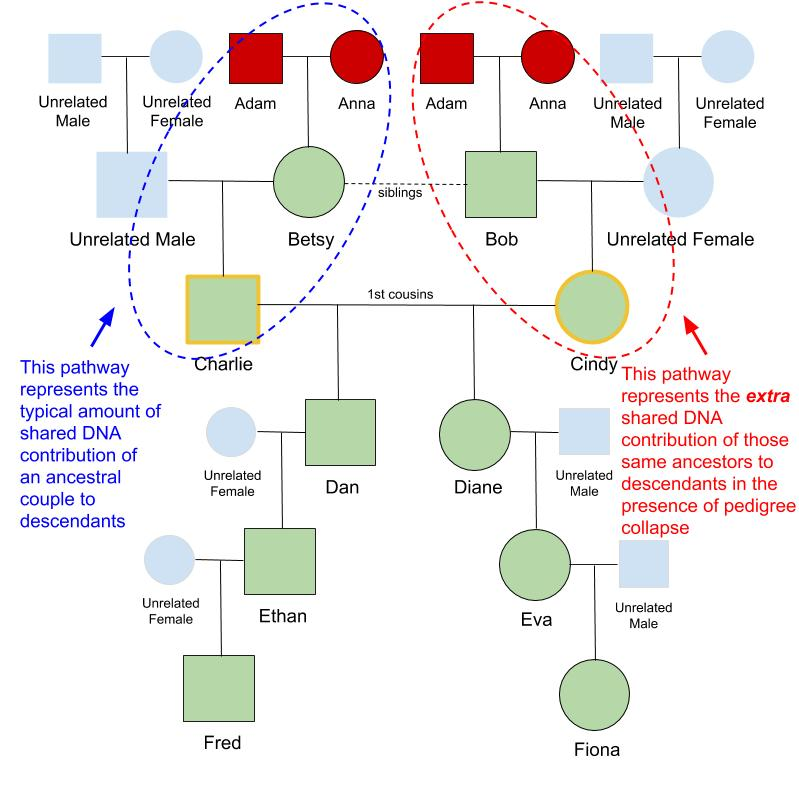
As with before, we will determine the distinct inheritance pathways and degrees of separation between Ethan and Eva, but this time through Adam and Anna. Because they are on the pedigree twice, there are separate paths that traverse each set of Adam and Anna. The first pathway analysis goes through the first set of Adam and Anna, and we will designate this as the one that represents the typical amount of shared DNA that a pair of ancestors would contribute to their descendants.

Remember though, we want to quantify the amount of increased DNA sharing over what would be the typical amount of DNA contribution from a single set of the same ancestors. To calculate the amount with which to augment the coefficient of relationship we will only include the analysis that comes through the extra set of Adam and Anna, as these are the inheritance pathways that provide the elevated DNA contribution.

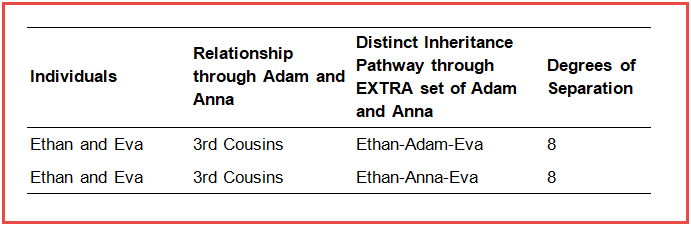
Using the same methodology for calculating the coefficient of relationship, we can determine the amount that this secondary relationship between Ethan and Eva would augment the numbers for their closer 1st cousin relationship.

Remember that Ethan and Eva are also 1st cousins, and are expected to share 12.5% of their DNA through that relationship. Shifting the focus to their secondary relationship as 3rd cousins through Adam and Anna, Ethan and Eva are expected to share an additional 0.781% of their genome over what would be expected in the absence of pedigree collapse due to the double-dose of Adam and Anna in their pedigree at the great-grandparent level. This translates into approximately 53 cM on average of elevated shared DNA between these 1st cousins who descend from grandparents who are also 1st cousins:
0.781% x 6800 cM = 53 cM

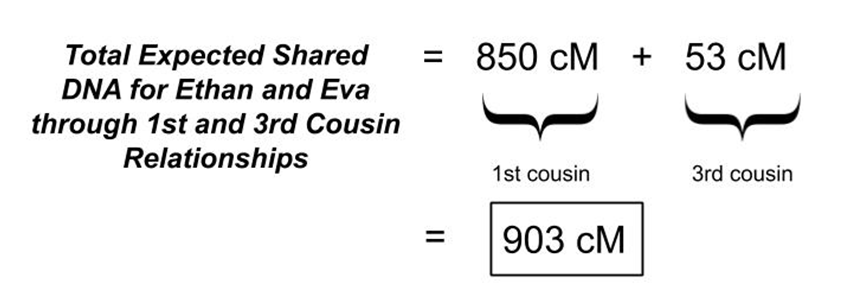
On average, the total amount of DNA that Ethan and Eva would expect to share is calculated by summing over all of their recent common relationships in the last several generations.
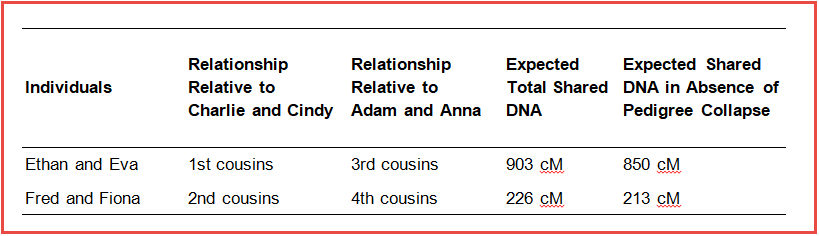
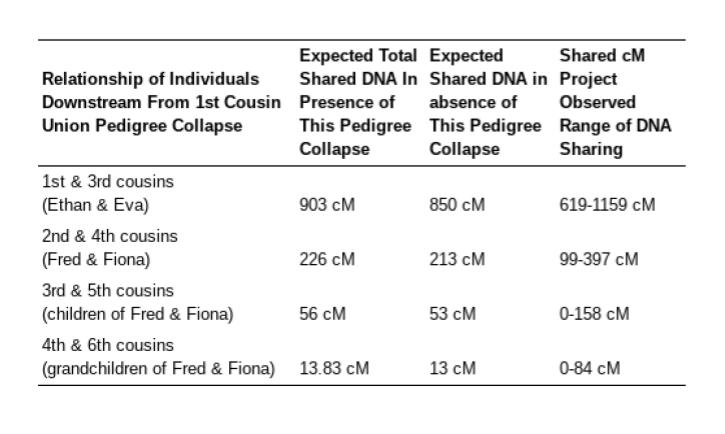
Ethan and Eva represent relatives who have a recent incident of isolated pedigree collapse in their ancestry. They are 1st cousins themselves, and they share grandparents who are also 1st cousins. Ethan and Eva are genetically more similar to one another than 1st cousins who have entirely-unrelated recent ancestors, so we expect them to have an elevated level of cM sharing. For 1st cousins in the absence of pedigree collapse, we expect that on average they would share 850 cM. For Ethan and Eva this level of DNA sharing is elevated on average by 53 cM, making an expected augmented average of 903 cM in the presence of this particular form of recent pedigree collapse.
It is important to note that these average shared DNA figures are just that: averages. This means that due to the random inheritance of DNA fragments of varying sizes at each generation, it is very possible that pairs of relatives will share DNA at levels higher or lower than the predicted average, but within a range that spans the average predicted amount. This is evident in shared DNA numbers compiled in the Shared cM Project (Table 1), as well as in data simulated by AncestryDNA, which predicts the ranges of cM sharing that are expected for various levels of relationship (see Figure 5.2 in this white paper). Information from these sources on the ranges of shared DNA expected statistically or observed empirically for various relationships is summarized in the table below.
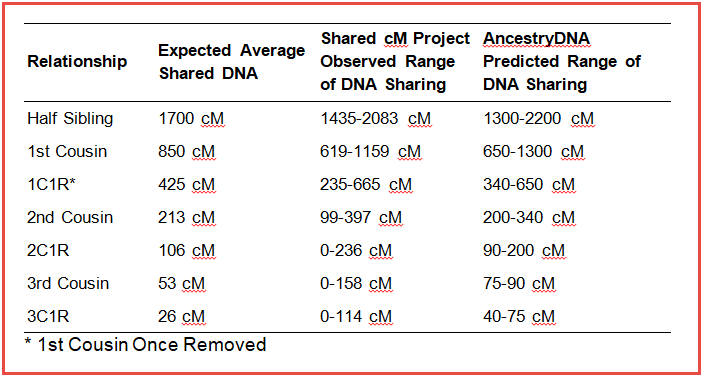
First cousins share on average 850 cM, but in practice 1st cousins report levels of DNA sharing in the range of 619-1159 cM (Shared cM Project), and AncestryDNA predicts statistically that they expect the amount of shared DNA to fall anywhere between 650-1300 cM. The recent pedigree collapse event in the pedigree of Ethan and Eva increases their average shared DNA as 1st cousins from 850 cM to 903 cM, but this elevated figure still falls well within the expected range for DNA sharing among 1st cousins. This isolated incident of pedigree collapse is not enough to inflate their amount of shared DNA to make them appear to belong to a different relationship category (half sibling or otherwise). They still fall solidly within the range expected DNA sharing for that of 1st cousins.
If you want to read even more about the amount of expected shared DNA between cousins with different relationships, read this article by fellow genetic genealogist Leah Larkin.
How much more DNA are these cousins sharing?
If Ethan and Eva were to encounter each other for the first time on a DNA company cousin match list, this exercise tells us that their increased DNA sharing would likely not be enough to tip them off to the fact that there is a recent occurrence of pedigree collapse in their shared ancestry. They still look a lot like just regular 1st cousins—1st cousins whose recent ancestors are entirely unrelated.
This proves to be true for other, more distant, cousin relationships downstream from this particular form of isolated pedigree collapse, where 1st cousins form a union and have children. The amount of shared DNA between 2nd cousins Fred and Fiona in the Colapso family who are what we call downstream from our pedigree collapse, is only elevated by 13 cM on average, because we are adding an additional 4th cousin relationship (through Anna and Adam) through their 2nd cousin relationship through Cindy and Charlie. (Note that while our empirical calculation says 13 cM, the Shared cM Project indicates that the average amount of shared DNA for 4th cousins is 35 cM, there are lots of fun reasons for this, but we aren’t going to talk about that right now). But no matter how you look at it, the shared DNA between Fiona and Fred is still compatible with the expected range of shared cM for second cousins without pedigree collapse. For downstream 3rd cousins (so Fiona and Fred’s kids), the amount of DNA sharing is only increased by 3 cM (the calculated added amount for their extra 5th cousin relationship), again keeping the total shared DNA well within the expected range. The effect of the pedigree collapse is lessened with each succeeding generation, as descendants become more distant from the “double-dose” ancestors that appear twice in their pedigree.
Because this is one of the closest forms of isolated pedigree collapse possible (the union of 1st cousins to produce children would only be upstaged in genetic similarity by the union of siblings, half-siblings, uncle-niece, and other immediately related relative pairs), it follows that more distantly related unions (2nd cousin and so forth) would have even less of an effect on the total shared DNA between downstream descendants. So cousins resulting from these more distantly related unions who encounter each other for the first time on a DNA company match list would likely see no evidence of this form of more distant and isolated pedigree collapse in their amount of shared DNA.
Multiplying effect of pedigree collapse
There are situations that some encounter in their ancestry where, unlike this example in the Colapso family with just one isolated incident of the union of related ancestors, there are many unions between related people at many generational levels. This situation produces much more widespread pedigree collapse where many of the same ancestors appear multiple times in the recent generations of a pedigree. In this case, there are many inheritance pathways that intertwine between relatives and unions, and children are produced from parents that are much more genetically similar than unrelated people.

What if you’re actually seeing endogamy, not just a couple instances of pedigree collapse?
Due to the now widespread accessibility of consumer genetic testing, often times downstream descendants in these families are encountering each other for the first time on a DNA company match list. Upon comparing pedigrees they find that their level of shared DNA is substantially elevated from what would be expected for the typical ranges of cM sharing for their closest relationship. See Kimberly T. Powell’s excellent book chapter, “The Challenge of Endogamy and Pedigree Collapse” in Debbie Parker Wayne’s Advanced Genetic Genealogy: Techniques and Case Studies (2019, p. 127-153), for examples of widespread pedigree collapse within an extended family and how it effects the level of cM sharing among downstream individuals.
Thank you for sticking with me through all that fun math, and learning more about pedigree collapse through several generations of the Colapso family! This exercise has introduced some of the issues that attend the interpretation of genetic data from a collapsed pedigree. The most global takeaway is that pedigree collapse always results in elevated levels of DNA sharing in the next several generations of descendants, but the farther away from the collapsing event the less effect it has on the shared DNA of descendants.
If the presence of pedigree collapse is isolated rather than widespread, downstream cousins will still expect increased DNA sharing but the elevated amount is modest enough to keep the augmented values well within the range of expected shared DNA for that relationship. Cousins will likely not recognize from their amount of shared DNA that they have an isolated incident of pedigree collapse in their recent pedigree.
This changes, however, if the incidents of closely related unions are widespread, as the augmented level of cM sharing among descendants may be enough to bump them up to a closer relative category. In the presence of widespread pedigree collapse, the same tools used to determine the coefficient of relationship among relatives can be applied and are a great help in deciphering the confounding and overlapping nature of relationships in these complicated pedigrees. And remember, if you encounter a cousin on a DNA match list who descends through a shared lineage with pedigree collapse, you may not recognize from the amount of shared cM that you are experiencing an elevated level of DNA sharing. But look closely at those numbers and see where you fall in the range of expected DNA sharing: you may find you are on the upper end.
Put these skills in action
Now that you understand more about how you may be related to your matches, take the next step and start learning how you can use your matches to find your ancestors. Our free downloadable guide, 4 Next Steps for your DNA, has simple, actionable steps you can take to get started!

