The best DNA ethnicity results—most accurate and specific—vary across testing companies. Here’s some hard data for 23andMe and AncestryDNA.
In my most recent post, I explained two key metrics in DNA ethnicity estimates: precision and recall. (The M&M analogy I used was pretty tasty, if I do say so myself.) In this conclusion to that post, I share what statistics on precision and recall have been published by our leading genetic genealogy companies.
Precision and recall in DNA ethnicity estimates

Haven’t tested with AncestryDNA yet? Learn more about AncestryDNA and find links to order DNA testing kits.
AncestryDNA ethnicity accuracy
The following table highlights just a few of the published precision/recall statistics obtained by AncestryDNA* in internal validation testing performed for the regions they support. [This specific data was obtained using synthetic test individuals with mixed ancestry, but the same concepts that describe precision and recall above continue to be applicable with this simulated data as well. The full table detailing the 43 regions evaluated is available in their 2018 Ethnicity Estimation White Paper].
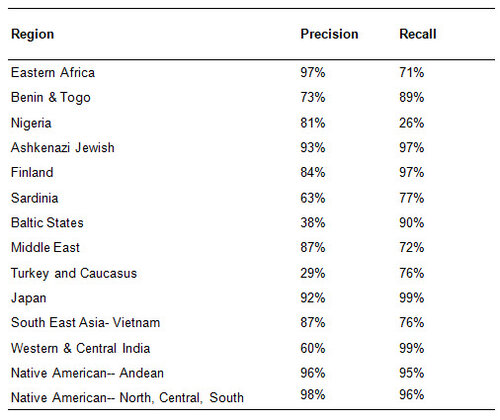
It is apparent that on all continents there are subregions that have strong performance indicators, and others that exhibit some problems with misclassifications. In the case of the Baltic States, precision was quite low (38%) so it was very common for test individuals with known ancestry from other geographies to be misassigned to the Baltic States, although recall was high (90%) so most individuals truly from the Baltic States were rarely misclassified. Testing for Nigeria shows that recall was low (26%) for this region with the algorithm frequently missing individuals with known Nigerian ancestry and assigning them elsewhere. Many regions exhibit very strong numbers in both precision and recall (many with >90% for precision and recall), which gives support to AncestryDNA’s ethnicity prediction process as being especially effective for these regions.
23andMe ethnicity accuracy
23andMe also publishes precision/recall statistics for some of the regions they support.

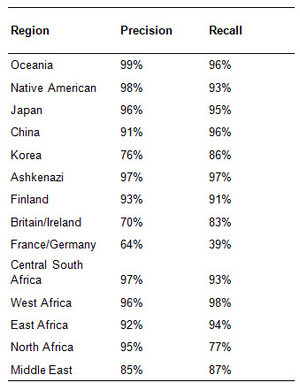
Many populations in the 23andMe ethnicity panel achieve strong precision/recall numbers, with several regions exceeding 90% for both. As was the case with AncestryDNA, there are also instances of low performance within certain geographies. France/Germany seems to be the most problematic with a lower precision measure (64%) indicating that individuals from other regions were often misassigned to this cluster, and lower still recall (39%) showing the converse problem that known French/German samples were frequently misclassified to other regions as well. With this data in hand, consumers are potentially able to make an educated decision about which company to use considering the populations that may be relevant to them. If a prospective client has reason to query for French/German genetic ancestry, a side-by-side comparison of precision/recall performance measures for available each company could be instructive.
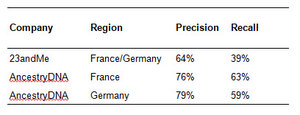
AncestryDNA actually splits the genetic populations for France and Germany, while 23andMe merges them into a single grouping. Each company made this decision based on performance indicators for each scenario (merged or split), and went with the grouping that achieved the best results in their internal tests. The reasons for the differing performance between companies for the same regions could be manifold, including the sampling density and diversity, and the specific workings of the proprietary algorithms in the way it interacts with the genetic characteristics of these populations in particular. The companies may argue that these precision/recall measures aren’t completely comparable because they weren’t obtained in a uniform way, but as a discerning consumer I would still find these numbers to be telling and indicative, and it would help me decide where to direct my financial investment.
Apparently, the bottom line is that however the companies arrived on slicing and dicing their data, the current published data gives AncestryDNA the edge on performance for France and Germany because (1) it provides greater resolving power to actually distinguish genetic ancestry between these two regions, and (2) it achieves better performance indicators in doing so.
More data needed on DNA ethnicity precision/recall
Unfortunately, this published precision/recall data is likely out of sync with the updated ethnicity prediction processes that AncestryDNA or 23andMe are currently using. They both indicate process updates since publishing that data. Industry wide, these measures and others are routinely reviewed internally and not released to the public. However, precision/recall are particularly telling and relevant indicators that can be easily digested by clients and would allow for educated selection of products to best serve their needs. Transparency on the side of industry has the benefit of increasing consumer confidence and also driving focused improvements that serve the paying client.
So let’s have it AncestryDNA, 23andMe, MyHeritage, LivingDNA, FamilyTreeDNA, and everyone else too. Publish your regionally-specific precision/recall data in a transparent location on your ethnicity reports, and also in a highly visible place in front of your paywall along with other autosomal ethnicity product information. This is good stuff. We want it!
Do you agree? Please contact your DNA testing companies and tell them so!
What to read next: Why DNA ethnicity estimates vary even for the same person—even at the same testing company!
Have you missed any of genetic genealogy expert Jayne Ekins’ must-read series on DNA ethnicity? Read them all!





